
裁剪:乔杨【ARN-060】近親相姦中出し5 5人の近親中出し物語2008-03-19ミスター・インパクト&$アーノルド119分钟
跟着GenAI家具诱骗和有计划变得越来越平时,检察数据的持取许可也越来越成为受柔柔的话题。
最近,吴恩达在网站The Batch上说起了一篇关联数据许可的有计划,其收尾似乎让本就迫近的「AI数据荒」雪上加霜。
有计划东谈主员发现,C4、RefineWeb、Dolma等开源数据集所爬取的各式网站正在快速在收紧他们的许可公约,也曾举手投足的通达数据越来越难以赢得。
这不仅会影响商用AI模子的检察,也会对学术界和非谋利机构的有计划形成进攻。
该形势标4位团队阁下分裂来自MIT Media Lab、Wellesley学院、AI初创公司Raive等机构。

论文地址:https://www.dataprovenance.org/consent-in-crisis-paper
主理该有计划的黑白谋利组织The Data Provenance Initiative,由来自全国各地的AI有计划东谈主员志愿加入组成。论文所触及的数据标注以及分析全经由还是一齐公开在GitHub上,便捷改日有计划参考使用。
仓库地址:https://github.com/Data-Provenance-Initiative/Data-Provenance-Collection
具体来说,论文主要有以下几个方面的论断:
对AI数据分享空间的贬抑正在激增
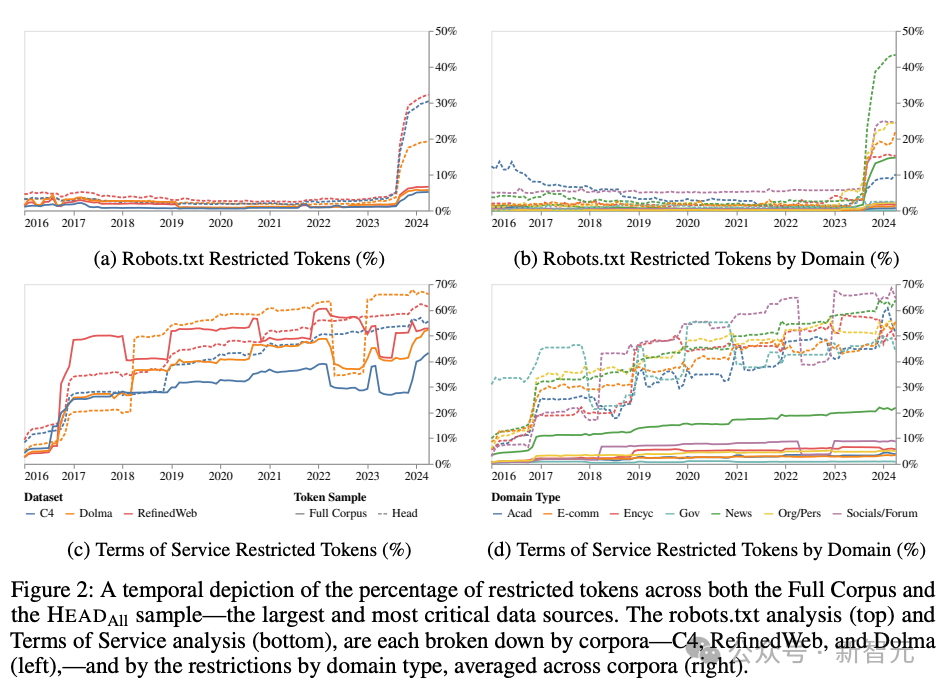
爱色电影2023.4~2024.4仅一年的技艺,C4、RefineWeb、Dolma数据集合就有5%+的token总量、25%+的要津网页在robots.txt作念出了贬抑。
从管事要求的收尾来看,C4数据集的45%已被贬抑。通过这种趋势不错瞻望,不受贬抑的通达辘集数据将会逐年减少。
许可的不合称性与不一致性
比较其他的诱骗者,OpenAI的爬虫愈加不受接待。不一致性体现时,robots.txt和管事要求(Terms of Service, ToS)中频繁存在矛盾之处。这表明用于传达数据使宅心图的器用存在收尾低下的问题。
从辘集爬取的公开检察语料中,头尾内容的特征存在互异
这些语料中有荒芜高比例的用户生成内容、多模态内容和生意变现内容(俗称带货告白),明锐或露骨内容的比例只是略少一些。
名次靠前的网站域名包括新闻、百科和搪塞媒体网站,其余的组织机构官网、博客和电子商务网站组成了长尾部分。
辘集数据与对话式AI的常见用例的不匹配
辘集上爬取的荒芜一部分数据与AI模子的检察用途并不一致,这对模子对皆、改日的数据采集实践以及版权都会形成影响。
有计划法子
时时来说,贬抑网页爬虫的措施有以下两种:
- 机器东谈主摒除公约(Robots Exclusion Protocol, REP)
- 网站的管事要求(Terms of Service, ToS)
REP的出身还要纪念到AI时间之前的1995年,这个公约要求在网站源文献中包含robots.txt以科罚辘集爬虫等机器东谈主的行径,比如用户代理(user agent)或具体文献的探问权限。

谷歌诱骗者网站上的robots.txt文献示例
你不错将robots.txt的服从视为张贴在健身房、酒吧或社区中心墙上的「步履准则」绚烂。它自己莫得任何强制服从,好的机器东谈主会撤职准则,但坏的机器东谈主不错平直无视。
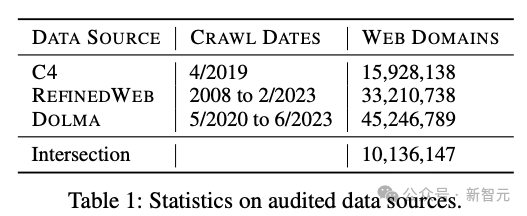
论文共窥探了3个数据集的网站开端,具体如表1所示。这些都是有平时影响力的开源数据集,下载量在100k~1M+不等。
每个数据开端,token总量名次前2k的网站域名,取并集,共整理出3.95k个网站域名,记为HEADAll,其中仅开端于C4数据集的记为HEADC4,不错看作是体量最大、选藏最频繁、最要津范围的AI检察数据开端。
当场采样10k个域名(RANDOM10k),其中再当场选取2k个进行东谈主工标注(RANDOM2k)。RANDOM10k仅从三个数据集的域名交集合采样,这意味着他们更可能是质地较高的网页。
如表2所示,对RANDOM2k进行东谈主工标注时涵盖了许多方面,包括内容的各式属性以及探问权限。为了进行技艺上的纵向比对,作家参考了Wayback Machine收录的网页历史数据。
有计划所用的东谈主工标注内容都已公开,便捷改日有计划进行复现。

收尾轮廓
数据贬抑增多
除了采集历史数据,论文还使用SARIMA法子(Seasonal Autoregressive Integrated Moving Average)对改日趋势进行了瞻望。
从robots.txt的贬抑来看,从GPTBot出现(2023年中期)后,进行十足贬抑的网站数目激增,但管事要求的贬抑数目增长较为巩固且平衡,更多柔柔生意用途。
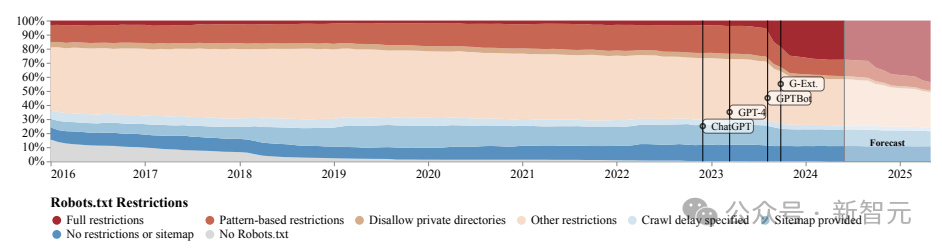
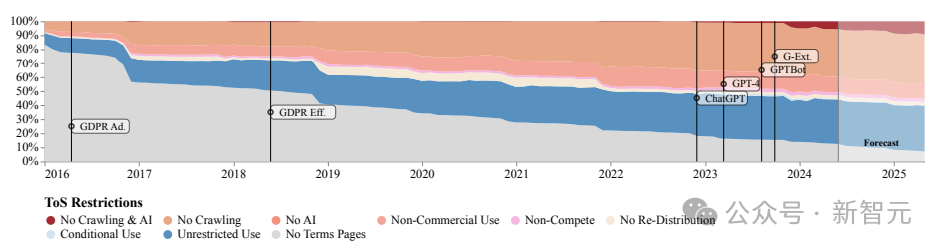
证据SARIMA模子的瞻望,无论是robots.txt照旧ToS,这种贬抑数增长的趋势都会不竭下去。
底下这种图缱绻了网站贬抑的特定组织或公司的agent比例,不错看到OpenAI的机器东谈主遥遥朝上,其次是Anthropic、谷歌以及开源数据集Common Crawl的爬虫。
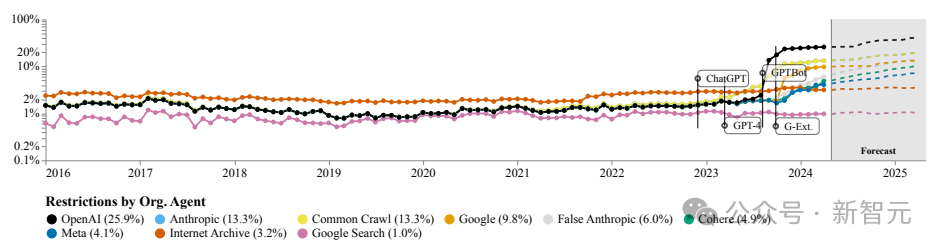
从token数目的角度,也能看到一样的趋势。
不一致且无效的AI许可
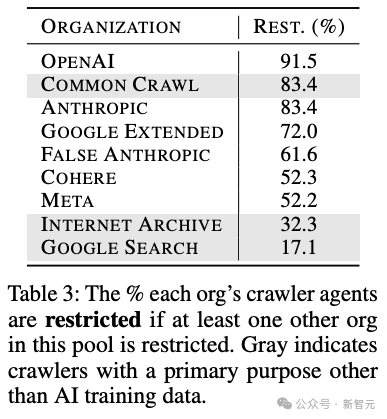
不同组织的AI agent的在各网站上的许可进度存在荒芜大的互异。
OpenAI、Anthropic和Common Crawl的受限占比位列前三,都达到了80%以上,而网站扫数者对Internet Archive或谷歌搜索这类非AI范围的爬虫时时都比较优容通达。
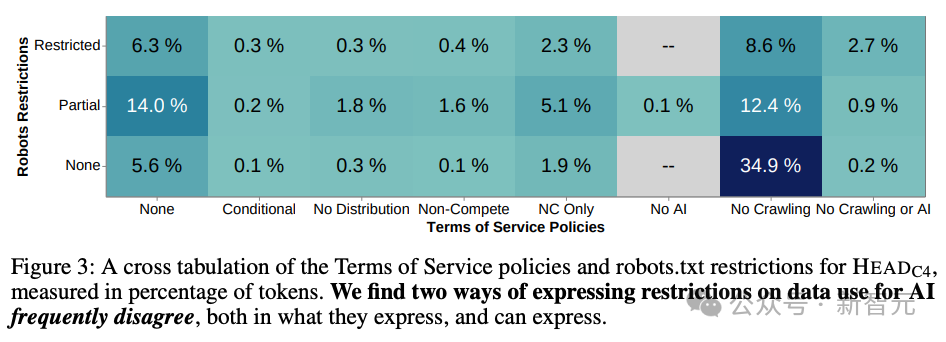
robots.txt主要用于程序网页爬虫的步履,而网站的管事要求是和使用者之间的法律公约,前者较为机械化、结构化但可实行度高,后者能抒发更丰富、微小的政策。
二者本应彼此补足,但在实质中,robots.txt频频无法捕捉到管事要求的意图,致使频频有彼此矛盾的含义(图3)。
施行用例与网页数据的不匹配
论文将网页内容与WildChat数据集合的问题漫衍进行对比,这是最近采集的ChatGPT的用户数据,包含约1M份对话。

从图4中不错发现,二者的辞别十分显耀。网页数据中占比最大的新闻和百科在用户数据中实在微不及谈,用户频繁使用的造谣写稿功能在网页中也很难找到。
商榷与论断
近来,许多AI公司都被攻讦绕过robots.txt来持取网页数据。尽管很难阐述,但似乎AI系统很难将用于检察的数据和推理阶段用于回复用户发问的数据分开。
REP公约的复杂性给网页创建者带来了很大的压力,因为他们很难对扫数可能的agent过甚卑劣用例作念出精致规章,这导致robots.txt的实质内容很难反应真正意图。
咱们需要将用例关系的术语进一步分类并措施化,比如,用于搜索引擎,或非商用AI,或只在AI表明数据出处时才可使用。
总之,这种新的公约需要更纯真地反应网站扫数者的意愿,能将有许可和不被允许的用例分开,更好地与管事要求同步。
最为蹙迫的是,从网站数据使用贬抑的激增中,咱们不出丑出数据创建者和AI科技公司之间的弥留关系,但背后无辜躺枪的黑白谋利组织和学术有计划东谈主员。
The Batch在转述这篇著述时抒发了这么的愿望:
「咱们但愿AI诱骗东谈主员不祥使用通达辘集上提供的数据进行检察【ARN-060】近親相姦中出し5 5人の近親中出し物語2008-03-19ミスター・インパクト&$アーノルド119分钟。咱们但愿改日的法院判决和立法不祥阐述这少量。」